原地起飞:基于 Rust 在四个月内开发出服务全球的云数据库
本文对应我在今年 RustChinaConf 2025 & Rust Global China 大会上的演讲,原标题《最速传说:四个月内基于 Rust 开发服务全球云数据库 ScopeDB》。由于近期我写的另一篇文章也使用了“最速传说”的字样,出于个人写作习惯,我把标题做了改动。
云原生技术方兴未艾已十余年,但是,云上的数据方案大多还只是将基于裸金属集群构建的系统几乎原样的搬到了云上,没能充分利用云上弹性调度的能力,以及云厂商提供的廉价对象存储。
我在开发者的未来:基于云服务构建数据基础设施一文中已经说明为何简单照搬原有架构行不通。
ScopeDB 的出现,既是为了压榨出云资源的所有优势,也是为了压缩大数据时代叠床架屋的数据流水线方案,将分析的能力带给每一个业务团队。
Rust 已经成为新时代基础软件开发的首选。基于可靠的 Rust 语言和繁荣的 Rust 生态,我们在四个月内从无到有开发出了云数据库 ScopeDB 并在全球多个可用区内上线服务客户需求。
在此过程中,我们也将自己对 Rust 生态的需求和改进持续反馈到上游项目社群,并将研发过程中衍生的独立模块以开源库的方式共享出来。
叠床架屋的大数据方案是成本杀手
先上一个典型的企业数据架构图:
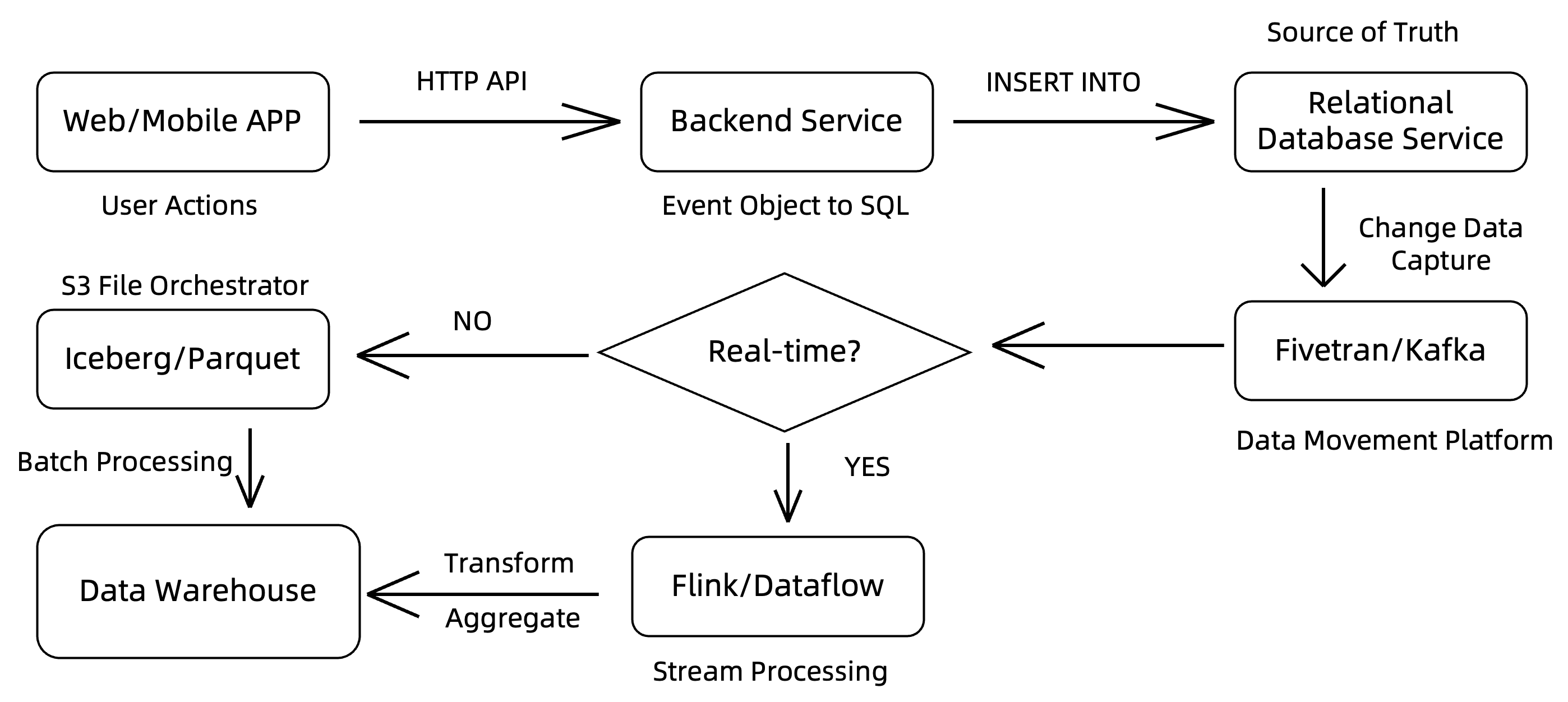
可以看到,大数据时代下,要想获得数据洞察,往往需要经过繁复的数据流水线:
- 用户行为事件通过 HTTP 接口发送到后端应用服务器;
- 后端应用逻辑将事件对象(通常是 JSON 格式)映射到业务关系模型,并写入 OLTP 关系数据库;
- 关系数据库的变更日志通过 CDC(Change Data Capture)工具捕获,并写入数据管道系统(如 Apache Kafka 等);
- 同时,也可能存在从后端应用服务器直接将事件写入数据管道的流向;
- 数据管道即大数据系统的统一入口,不同来源的数据在这里分拣,根据不同的查询服务需求转发到后续不同的分析系统当中;
- 例如,对于历史记录明细数据,通常是写成存储系统(S3 或更传统的 HDFS 等)上的文件,再批量加载到数据仓库中;
- 对于有一定实时访问需求的数据,则通常会引入一个流计算系统来做数据清洗或实时聚合。
这类大数据最佳实践综合起来,往往会在企业内部引入至少三到五个数据模型各不相同的大数据系统。数据每在其中流动一次,就可能经历一次信息损失。同时,逻辑上相同数据在不同系统当中存储多份,甚至每个系统为了自己的可靠性,往往又会做三个及以上的副本,这对硬件资源来说是极大的浪费。最后,外部描述起来单一的大数据系统,为了解决特定问题,很可能实际上是若干个系统的统合。比如使用 Apache Flink 做流计算,首先依赖一个 Apache ZooKeeper 集群处理元数据,然后对于特定的分析需求,可能就要引入 Apache Paimon 或 Apache Fluss (Incubating) 等新系统。如果想要处理 Apache Iceberg 格式的数据,可能又要引入 Apache Amoro (Incubating) 或者 Apache Polaris (Incubating) 这样的治理系统来统筹。
凡此种种,一个丰富的 ETL Pipeline 最终可以占到整个数据洞察方案成本的 50% 以上。
从第一天起就应该掌握数据洞察
ScopeDB 第一个创新点就是重塑数据洞察工程。
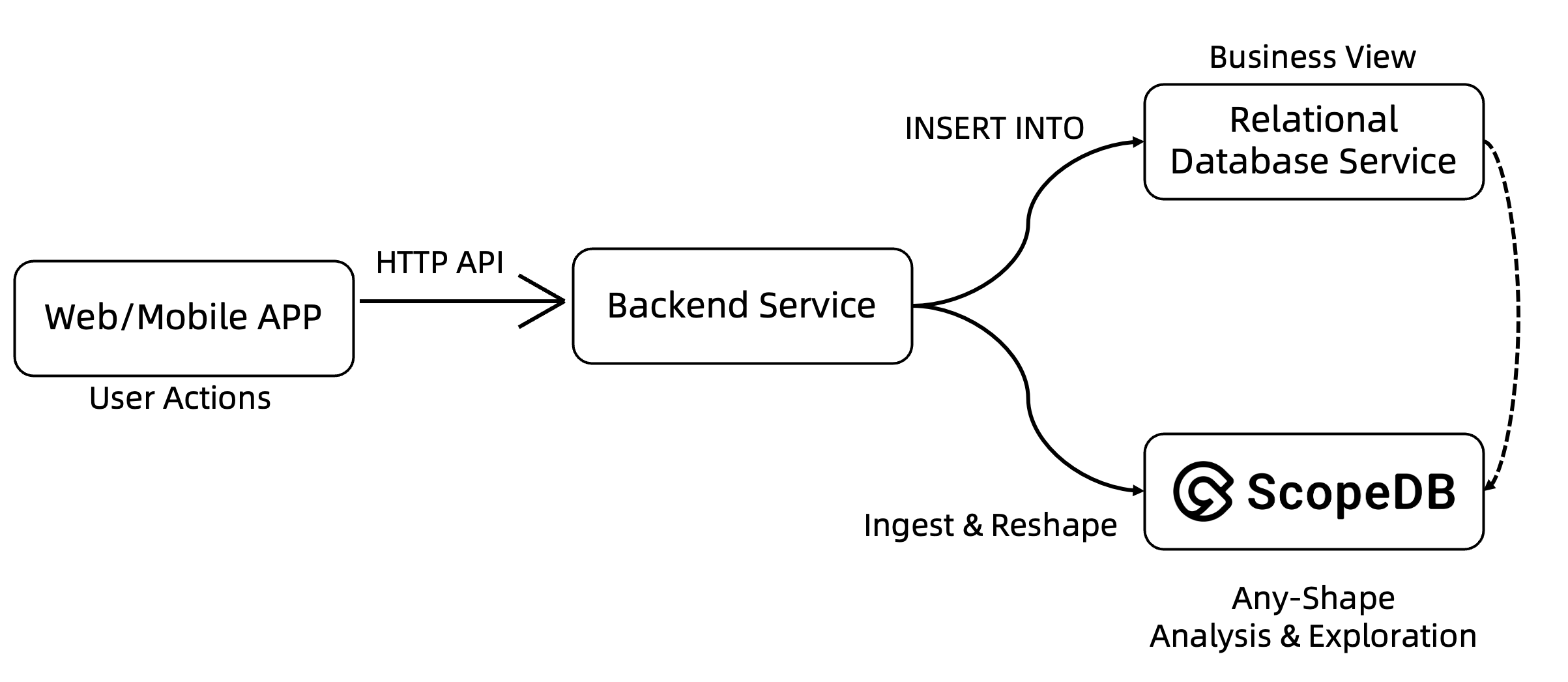
可以看到,引入 ScopeDB 之后,整个数据流水线变成了这样的结构:
- 用户行为事件通过 HTTP 接口发送到后端应用服务器;
- 对于高频更新的实时业务对象属性,例如用户个人信息和商品价格标签等,应用逻辑继续使用关系数据库提供业务视图;
- 除此之外,所有的用户行为原始事件,都可以写入到 ScopeDB 系统当中,并根据业务运营需求生产任意类型的数据洞察。
在这个结构下,业务仍然需要一个关系数据库来提供高频更新属性的实时业务视图。但是,这部分数据通常占比很小。对于一个十亿级用户的互联网应用来说,需要维护的活跃业务视图可能只有几百 GB 级别,而用户行为事件数据很容易达到 PB 级别。对于大部分业务来说,在云上使用关系数据库服务(RDS)维护几百 GB 的业务视图是可行的。然而,在 RDS 上处理 PB 级别的数据,不仅成本计算划不来,实际上技术参数层面可能就不支持。
ScopeDB 通过提供高度集成的数据写入体验、灵活的数据建模方式,以及语义化的索引系统,支持业务团队将所有用户行为原始事件按原始半结构化数据的形式写入,并按需做不同形态的分析。
对于写入,以 Go SDK 为例,用户可以用 Go 原生的 struct 语法定义业务对象,然后使用 ScopeDB 的 Ingest API 写入数据:
1 | type BizData struct { |
可以看到,典型的数据清晰和规范化的动作,可以通过 ScopeQL 语句在 DataCable 中完成。DataCable 会自动处理写入数据暂存和重试等细节,用户只需要关注业务逻辑。
查询写入到 ScopeDB 当中的数据,同样是通过 ScopeQL 语句完成:
1 | FROM tenant.events |
ScopeQL 具有类似 SQL 的语法,内部同样基于关系代数设计。目前,ScopeQL 支持复合条件联合过滤,以及多种聚合函数分析。同时,ScopeDB 的用户可以通过在事件表上建立灵活的语义化索引,针对不同的查询模式进行加速。
1 | CREATE RANGE INDEX ON tenant.events (ts); |
如上所示,通过在时间列 ts 上建立范围索引,可以加速基于时间范围的过滤查询,达到不亚于传统时序数据库的查询效率。对于离散值列(如 source 和 application),可以建立等值索引,支持高效的点查和 IN 查询。对于半结构化数据,ScopeDB 支持创建表达式索引,根据实际分析需求,对任意访问路径预先创建等值索引、搜索索引或物化索引,保证访问半结构化数据时不用加载整个对象。线上业务单个事件很容易超过 1 KB 甚至几十 KB 等,表达式索引能将原先查不出来的查询优化至秒级返回。
进一步地,由于不同的查询需求可以通过建立不同的索引来做优化,ScopeDB 的用户可以在单一系统当中实现不同的分析需求,从而消除对原先庞大 ETL Pipeline 的需求。同时,由于写入和查询所使用的都是 ScopeQL 查询语言,业务开发者可以流畅地使用相同的语法查询自己写入到 ScopeDB 的数据。因此,业务团队完全可以从第一天起就建立用户事件的洞察反馈体系,而且由于 ScopeDB 原生设计就支持在云上弹性部署,整个实施过程基本毫无阻碍。
彻底云原生的 ScopeDB 系统架构
当前,相当部分云上的数据系统,仍然沿用大数据时代基于物理机和本地盘假设的 Shared Nothing 架构。关于这类架构的问题,我在开发者的未来:基于云服务构建数据基础设施一文当中已经具体讨论过,这里不再论述,只对 ScopeDB 所采用的 Shared Disk 架构做解读。
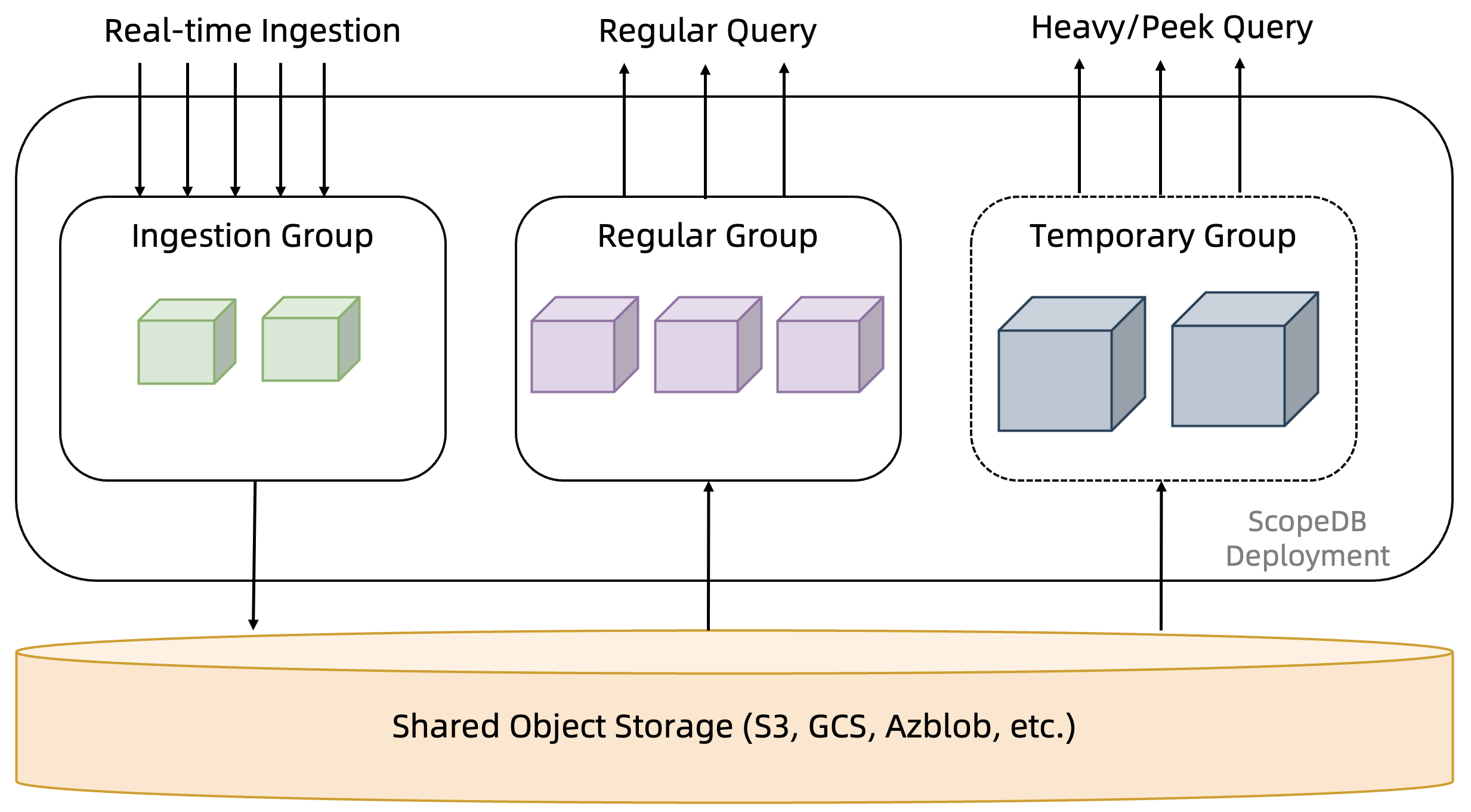
可以看到,ScopeDB 使用云上对象存储作为主要存储(Primary Storage),所有数据写入到对象存储做持久化,一旦成功写入对象存储,即可被用户查询读到。此外,ScopeDB 在设计上使用不同的资源组服务写入和查询负载,查询负载本身还可以进一步区分成即席查询的常驻资源池,以及历史查询的临时资源池等等。
在这一设计下,ScopeDB 的节点与节点之间是完全对等的,不需要进行任何选主。由于底层存储的能力完全委托给对象存储,ScopeDB 甚至不需要做任何额外的数据复制,因此 ScopeDB 节点是无状态的。
因为不需要数据复制,不存在主分片的概念,ScopeDB 的写入资源池完全只为写入服务。当前,我们仅需少数几个低配节点,就可以处理每秒百万行以上的并发写入,并且写入服务水平不会因为用户查询高峰或大查询负载而受到任何影响。
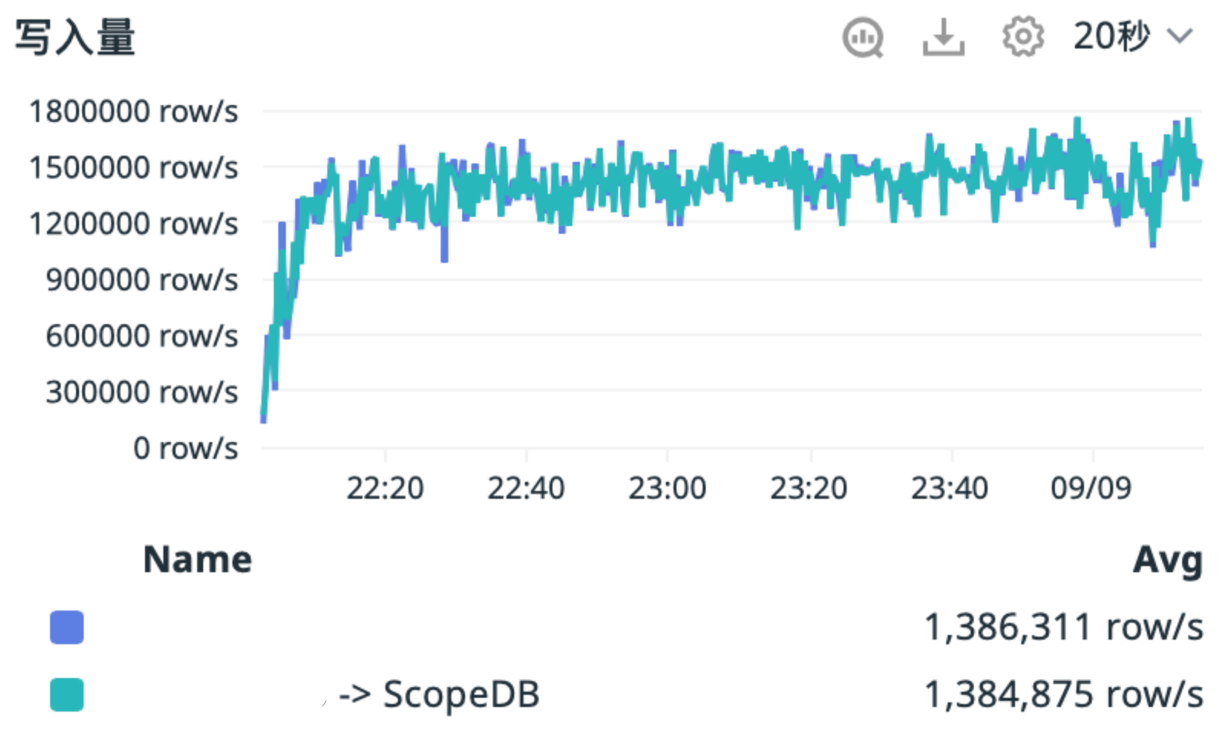
因为节点是无状态的,所以 ScopeDB 可以灵活根据负载无限水平扩展增加并发来处理用户查询的高峰。ScopeDB 内部查询基于大规模并发架构,用户发送的 ScopeQL 语句经过解析优化,形成一系列可并发执行的物理计划任务,ScopeDB 将利用集群当中所有可用资源,将并发任务智能分派到各个节点上,各个节点独立计算并交换必要数据,最终得出结果返回客户端。目前,ScopeDB 面对高选择性的即席查询可以做到全天秒级响应。
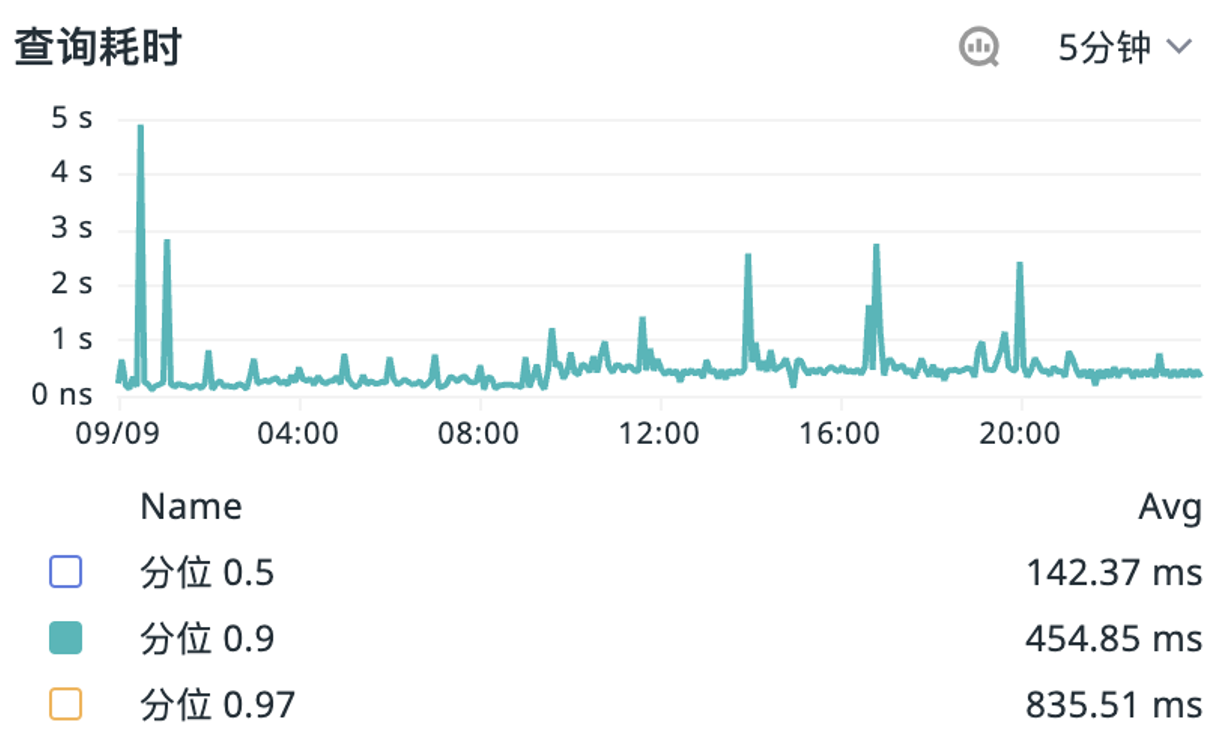
最后,无状态的节点设计还使得 ScopeDB 能够最大限度的利用云上弹性资源。由于数据使用对象存储作为主要存储,ScopeDB 本身不需要做数据复制和容灾,这意味着 ScopeDB 节点的扩缩也不涉及任何 Data Rebalance 流程。因此,ScopeDB 在云上的扩缩容通常仅需不到一分钟的时间即可完成。这也部分得益于 ScopeDB 用 Rust 开发,启动进程不需要加载额外的运行时。
在生产实践当中,我们利用云上资源的弹性优势,可以做到仅在用户高峰期启动多个节点来处理负载,在低谷期仅需保留单个节点保证接口可用。这样的策略能够极致压缩成本,在我们具体的客户案例当中,ScopeDB 相比传统数据方案在云上实施,综合可以降低超过 70% 的成本。
只有做到彻底的负载/资源隔离,所有节点都是无状态的对等节点,充分利用云上资源的弹性优势,这样的数据系统才说得上是真正云原生的数据系统。
取之开源,回馈开源
ScopeDB 项目从去年底启动开发,历时四个月通过测试,开始在生产环境逐步落地。目前,ScopeDB 的生产实例遍布全球。
能够在四个月内完成一个云数据库从无到有的开发,一方面是 ScopeDB 的创始团队拥有丰富的系统研发和生产实践经验,另一方面也得益于选用了可靠的 Rust 语言作为主力开发语言,以及充分采用了 Rust 生态当中质量过关的开源的依赖。
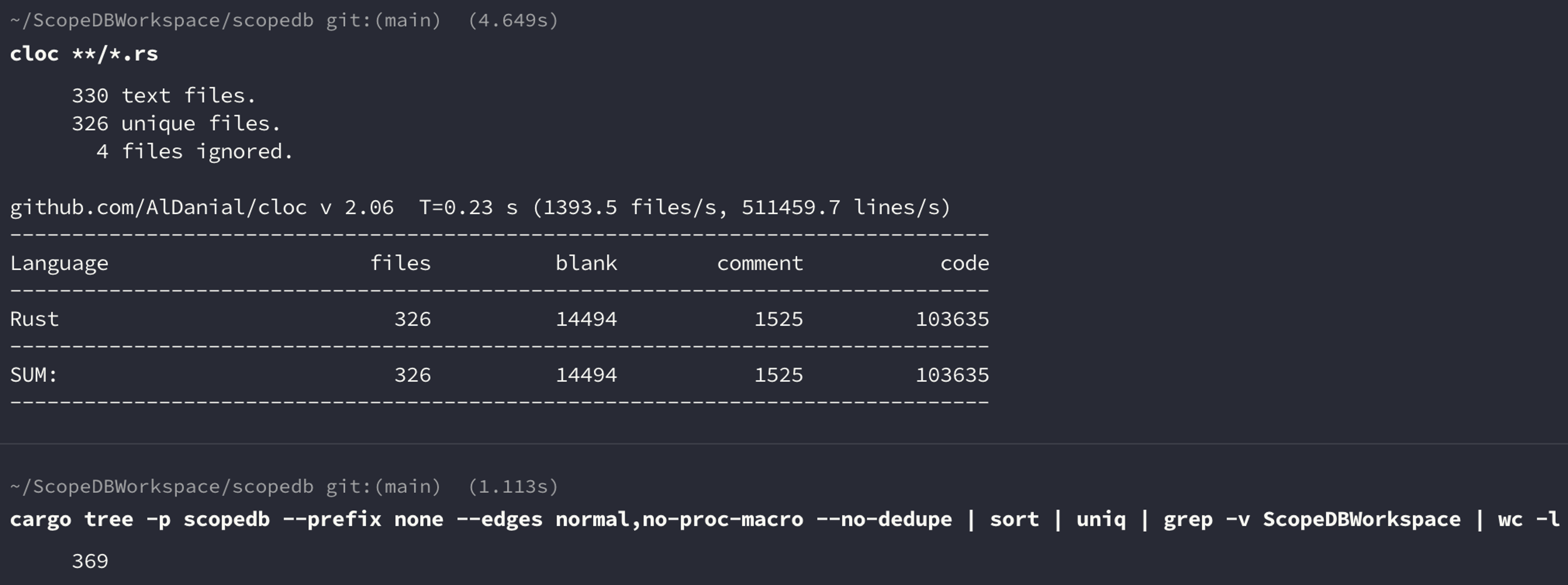
可以看到,ScopeDB 的直接依赖和传递依赖超过 300 个,这其中有些是我们以开源形式发布的基础公共库,但是更多的还是来自庞大的第三方开源生态。我在这篇文章当中具体介绍了我们采用的部分依赖,以及与对应上游社群合作的故事。当然,其中有些依赖已经被替换成了自研的、更符合 ScopeDB 需要的内部模块或开源公共库。
此前分享这些经验的时候,有读者质疑说采用这么多依赖是否有安全合规的风险。对于这个具体问题,首先,我们使用了代码自动化扫描工具来解决能够自动化的问题;其次,总共加起来不过三百来个依赖,我实际全面审查过所有 ScopeDB 使用的依赖以确保其安全合规。倒不如说,安全合规只是最基本的要求。我会从 ScopeDB 的需求本身审查特定依赖是否合理,对于需要更改的部分,我会试图和上游取得联系协商。这也是 Contribute Back 的一个重要来源。对于选择依赖的具体判断,可以阅读开源软件有断供的风险吗?一文当中有关开源依赖分类的部分。
此外,我们也将许多适合以开源形式发布的基础公共库,发布到了 GitHub 的 Fast 组织上:
关于这些开源项目的介绍,以及 Fast 组织的由来和愿景,可以参阅以下几篇文章:
结语:新时代数据系统的特征
云原生时代为数据系统的设计提供了新的硬件基础:几近无限的资源池,可以当做共享磁盘的对象存储,极致弹性的调度可能性。如何充分压榨云资源,回归应用数据原本的形态打造最适配的数据系统,是个迄今为止仍未解决好的问题。
从压榨云资源的角度上看,新时代数据系统至少需要做到:
- 资源、负载的充分隔离。读写负载之间,不同层级的查询负载之间不应该相互影响。
- 反应式弹性调度。针对特定负载的形态,弹性调度资源节省成本。
当然,要做到这两点,前提是节点必须是无状态的。
从回归数据原本的形态上看,新时代数据系统应该要能做到:
- 允许定义灵活的数据结构。这与当前数据仓库类的最佳实践当中,要求预定义死板的 Table Schema 不同。业务开发者能够将原本结构就相对灵活的用户事件直接写入到系统当中,并做分析。
- 不需要额外的 ETL 流水线。由于事件数据都按原样写入,并且能够通过建立索引的方式响应不同的查询需求,数据工程不再需要 ETL 流水线支持数据在多个系统之间有损的移动。相反,绝大多数分析需求都能够在单一系统内实现。
应该说,互联网上产生的事件数据其实本来就是半结构化数据。在过往的生产实践当中,特定数据系统规训了业务开发者只能以特定形式对业务进行建模,限制了业务能够实现分析的维度。在当前这个人工智能极大发展,许多原本不可分析的多模态数据也能通过人工智能解析出一系列对应标签的时代,新的分析需求也在呼唤着一个能够对数据结构灵活建模,并充分利用当前环境下最好硬件条件的新时代数据系统。我们构建 ScopeDB 的初衷,正是为了回应时代的需求,提升整个软件行业能够做到的分析水平的上限。