担任 ASF 董事会成员及技术创业
本文整理自《对话 tison - 新晋国际开源基金会董事,95 后创业者》,但是内容是按照原来设计的问题列表介绍我今年的新关注点,与播客节目实际聊天的内容不完全一致。以下是问题列表:
本文整理自《对话 tison - 新晋国际开源基金会董事,95 后创业者》,但是内容是按照原来设计的问题列表介绍我今年的新关注点,与播客节目实际聊天的内容不完全一致。以下是问题列表:
近期若干开源组织进行换届选举。在此期间,拥有投票权的成员往往会热烈讨论,提名新成员候选人和治理团队的候选人。虽然讨论是容易进行的,但是实际的投票流程和运作方式,在一个成员众多的组织中,可能会有不少成员并不清楚。
本文以 Apache 软件基金会(Apache Software Foundation, ASF)为例,介绍 ASF 所采用的投票方式。
最近一个多月没有发布新的文章,我把时间大多投入在实践验证自己在多次演讲中都描绘过的开源孪生模式上。

本文展开介绍上图提及的各个具体实践,并说明这一模式如何可持续发展。
近期,Linux 上游因为受美国出口管制条例的影响,将移除部分开发者的 MAINTAINER 权限,引起了新一轮对开源依赖的重新评估。
关于其中开源精神和社群治理的讨论,卫 Sir 的两篇文章已经讨论得比较清楚(见尾注)。本文主要从软件供应链的角度出发,回应对“开源软件的断供风险”的担忧。
简言之,开源协议只是向用户授权自由使用特定版本源代码。除此以外,大部分开源协议都明确声明不提供维保,更不承诺有一个长期迭代的上游分支。
上周在北京参与了开源社主办的 2024 中国开源年会。其实相比于有点明显班味的“年会”,我的参会体验更像是经历了一场中国开源的年度嘉年华。这也是在会场和其他参会朋友交流时共同的体验:在开源社的 COSCon 活动上,能够最大限度地一次性见到所有在中国从事开源相关工作的人。
我在本次会场上有两个演讲,分别是 Rust 分论坛上分享的《高性能 Rust 编程:如何减少数据拷贝和并发开销》,以及开源运营分论坛介绍的《商业开源如何重塑社群信任》。本文将简要介绍我的分享内容,以及参会的见闻纪实。
首先介绍一下我在 Rust 标准库当中做的两个微小的工作。
第一个是从去年 8 月 14 日发起,今年 4 月 6 日合并,历时约 8 个月,目前仍在等待 stabilize 的为 OnceCell 和 OnceLock 增加新接口的提案:
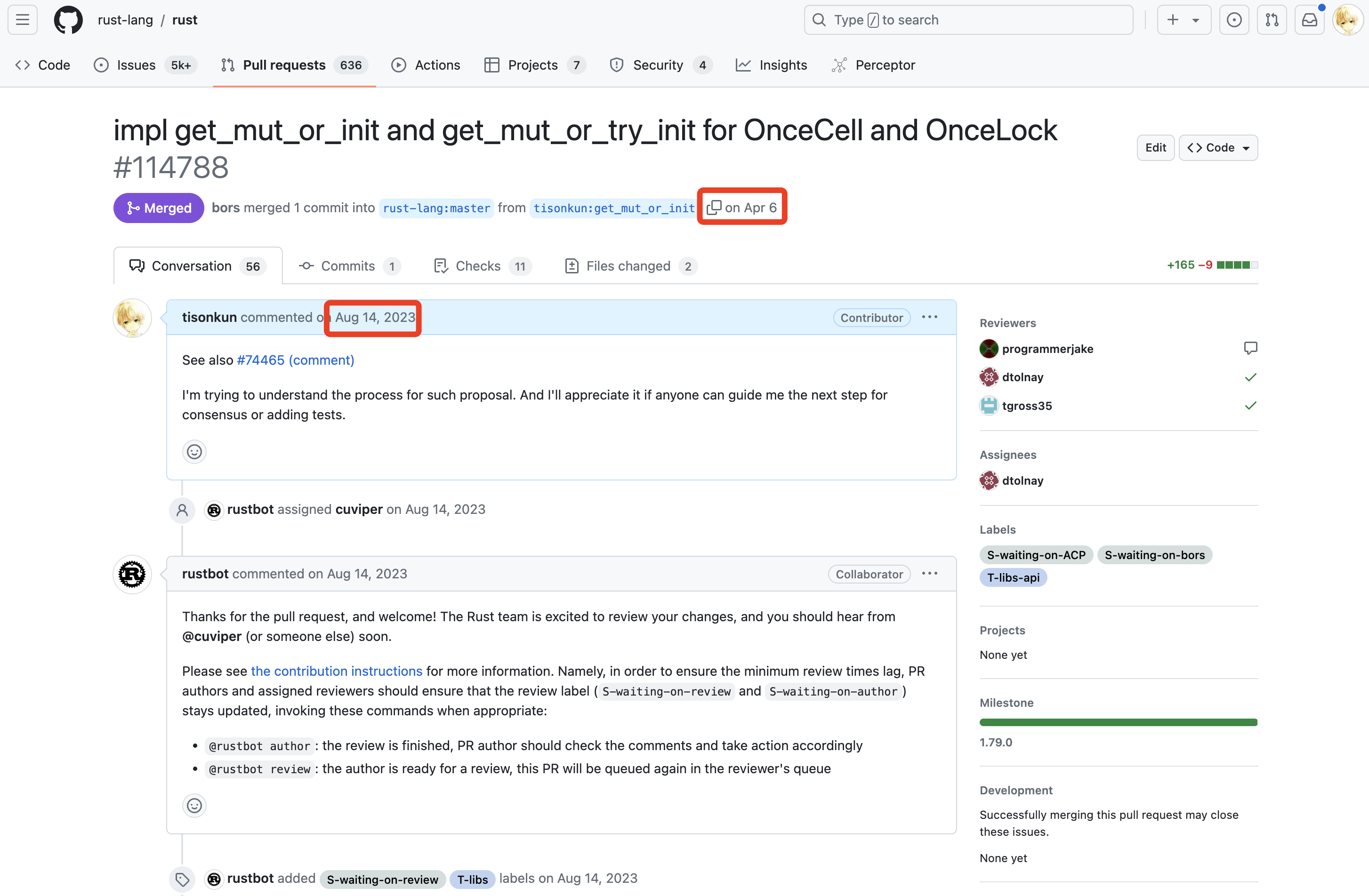
第一次贡献成功合并后,马上第二个工作是从今年 4 月 8 号开始,7 月 6 号合并,历时约 3 个月,同样还在等待 stabilize 的为 PathBuf 和 Path 增加拼接扩展名新接口的提案:
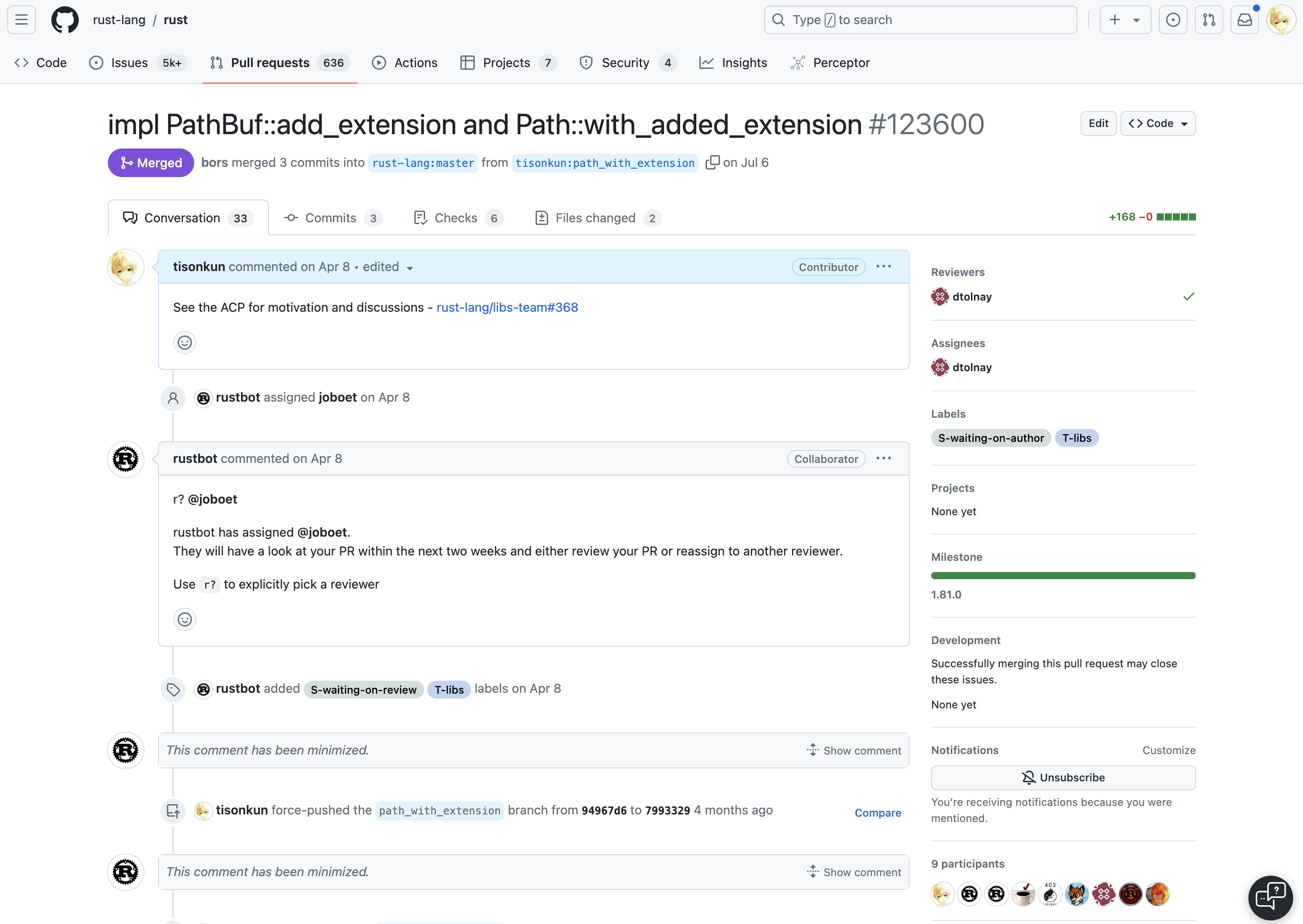
可以看到,这两次贡献的内容可算是同种类型的,第二次提交从发起到合并的时间比第一次缩短了一半以上。本文先介绍 Rust 标准库提案的基本工作流程,然后介绍这两个贡献背后的故事,最终讨论开源贡献的源动力从何而来。
CommunityOverCode Asia 2024 于 7 月 26 日到 28 日在杭州举行。其前身是 Apache 软件基金会一年一度的 ApacheCon 活动,通常会在多地分别举办。今年已经举行的是本次亚洲大会,以及 6 月在斯洛伐克举行的欧洲大会。10 月,北美大会将在丹佛举行,我也会在北美的会议上分享两个主题:
欢迎届时关注。
本文分享我在刚刚过去的 CommunityOverCode Asia 2024 大会上的见闻和体会。
6 月 24 日,我在北美湾区参与了一场线下的 Apache DataFusion 聚会活动。
其实我是 6 月 21 日才到的旧金山,6 月 18 日才发现湾区有这样一场线下活动。不过或许得益于我在今年在 DataFusion 做过几次贡献,GreptimeDB 是 DataFusion 在行业顶级的应用标杆,会议组织方很干脆的就增加了一个 Speaker 席位,让我能够做在聚会上做题为《Boosting a Time-Series Database With Apache DataFusion》的演讲。
本文是 GreptimeDB 首位独立 Committer Eugene Tolbakov 所作。
在上一篇文章《GreptimeDB 首位独立 Committer Eugene Tolbakov 是怎样炼成的?》当中,我从社群维护者的视角介绍了 Eugene 的参与和成长之路。这篇文章是在此之后 Eugene 受到激励,从自己的角度出发,结合最近为 GreptimeDB 改良 SQL Interval 语法的实际经历,分享他对于开源贡献的看法和体验。
以下原文。
近年来,时序数据的增长是 Data Infra 领域一个不容忽视的趋势。这主要得益于万物互联带来的自然时序数据增长,以及软件应用上云和自身复杂化后的可观测性需求。前者可以认为是对联网设备的可观测性,而可观测性主要就建构在设备或应用不断上报的指标和日志等时序数据上。
分析时序数据的演变史几乎是大数据分析演变史的复现,即一开始都是把数据存在关系型数据库上,使用 SQL 分析;而后由于规模增长的速度超过传统技术增长,经历了一个折衷技术的歧出;最终,用户在 SQL 强大的理论框架和生态支持的影响下,回到解决了规模问题的 SQL 方案上来。
对于时序数据来说,这一歧出造成了大量时序数据库自创方言。其中以 InfluxDB 在 V1 版本创造了 InfluxQL 方言,在 V2 版本创造了 Flux 方言,又在 V3 里开始主推 SQL 的演变过程最为有趣。