GreptimeDB 社群观察报告
GreptimeDB 是格睿科技(Greptime)公司研发的一款开源时序数据库,其源代码在 GitHub 平台公开发布。

我从 2022 年开始知道有 GreptimeDB 这个项目。2023 年,我注意到他们的 Community Program 是有认真写的,不是无脑复制所谓成功项目的大段规则,于是开始跟相关成员探讨开源治理和社群运营的话题。后来,我读过 GreptimeDB 的源代码,发现他们的工程能力很不错,于是就开始参与贡献。
经过这几个月的参与,我对 GreptimeDB 的社群有了初步的了解。我认为,这是一个值得参与的拥有巨大潜力的开源社群。于是写作这份社群观察报告做一个简单介绍和畅想。
GreptimeDB 的社群量化情况
两年前,曾有人半开玩笑地说 Rust 和时序数据库都快成开源世界的一个梗了,因为当时有大量的 Rust 语言写作开源项目和定位在时序数据库的开源项目出现。GreptimeDB 也算其中一员,它同样是用 Rust 语言写成的。
不过两年过去,回过头看能够坚持下来不断发展的项目,GreptimeDB 就是为数不多硕果仅存的一员。哪怕跟主流时序数据库项目社群相比,GreptimeDB 的活力也可圈可点。
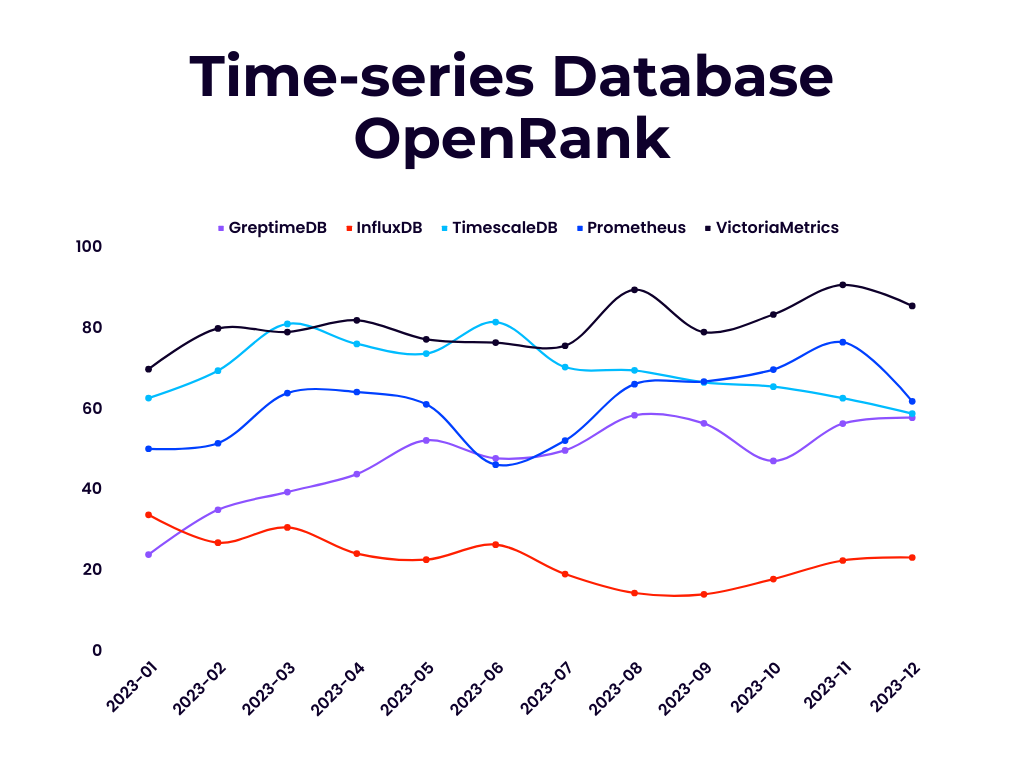
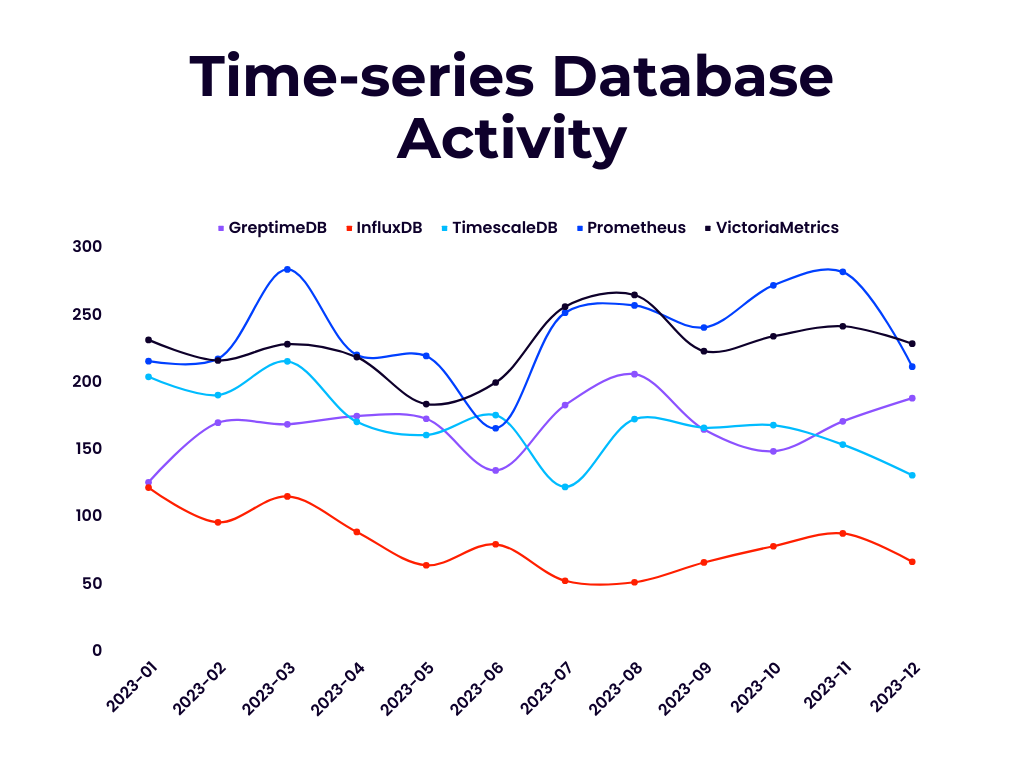
上面两张图展示了 2023 年,即 GreptimeDB 开源运营第一年,从 OpenDigger 数据集生成的每月 OpenRank 和活跃指数(Activity)数据折线图。
可以看到,从 OpenRank 的维度看,GreptimeDB 显著超越了近年来发展乏力的 InfluxDB 项目,跟 TimescaleDB 和 Prometheus 不分伯仲,相比起战斗民族出品的商业开源产品 VictoriaMetrics 仍有差距。从项目活跃指数的维度看,GreptimeDB 则与 InfluxDB 之外的主流项目同属第一梯队。
OpenRank 是同济大学赵生宇博士定义的一个开源价值流分析指标。相比于容易受先发优势影响的 Star 数和 DB Engines 分数等指标,上面展示的每月 OpenRank 和 Activity 变化情况更能体现出项目当前的发展情况和未来趋势。
GreptimeDB 的社群运营情况
前面提到,我真正开始关注 GreptimeDB 社群的契机是发现他们的 Community Program 并非船货崇拜,而是明显经过思考,有一定可行性的。事实证明,确实如此。2023 年 GreptimeDB 按照 Community Program 的设计发展了两名公司之外的 Committer 新成员:
- Biweekly Report (Jun.5 - Jun.18) – A Key Milestone, First External Committer Onboard
- Biweekly Report (Jul.17 - Jul.30) – Welcome the Second External Committer!
这两位 Committer 都是通过代码贡献被提名的,提名前都提交了大约二十个代码补丁,且质量被项目团队所认可。此外,这两位 Committer 从开始参与项目发展到成为 Committer 都经过了若干个月的持续投入。可以看到,这个标准下筛选和认可的两位 Committer 在上个月仍然有活跃参与。
应该说,目前 GreptimeDB 的项目功能已经初具规模,能够达到线上交付的标准。这也意味着开荒阶段的大量初创工作已经完成,新加入的社群成员可以在一个坚实的工程基础上发挥自己的创造力。同时,GreptimeDB 在实现优化上还有很大的进步空间,倒排索引、WAL 和存储引擎等技术方向上还有很多未解决的设计实现问题。现在仍然是参与 GreptimeDB 成为 Committer 的机遇期。
不过,GreptimeDB 的 Community Program 距离成为一个商业开源标杆还有不少可以改进的地方。
例如目前邀请新的 Committer 只在 Biweekly 上简单提及。Community Program 设计的结构上并没有即时体现出它正常运转,以及社群存在公司之外的 Committer 的事实。对于活跃参与者和 Committer 的介绍和成功经验分享,也尚有欠缺。目前社群基本处于给代码写得好的人一份权限的朴素运营阶段。
此外,Community Program 虽然已经相比其他船货崇拜的同行删减了许多内容,以保证它能够务实地运作,但是仍然存在一些空洞的组织结构。例如设计出的 Steering Committee 做技术和社群发展决策,但是实际上当前阶段大部分工作就是公司团队商议决定后公开;例如还是定义了 SIG 乃至 OSPO 的组织,但是根本没有人力填充运营这些机构。
我认为,Community Program 应该继续依托当前社群实际运行的状态,结合期望达成且有能力达成的下一个状态,来做修订。例如,提高成为 Committer 的标准和路径的透明性,积极分享案例和邀请 Committer 说出自己的故事。例如,精简冗余和虚假的组织架构的同时,保留在社群征求意见和决策结果向社群公开的关键动作。例如,强调社群成员参与渠道的多样性,鼓励在不同渠道帮助他人使用 GreptimeDB 和参与贡献。这部分是 Ambassador/Advocate 的核心。
除了这个堪称开拓性探索工作的 Community Program 之外,GreptimeDB 社群还有两件事情让我印象深刻。
第一个是 GreptimeDB 社群积极参与开源之夏这样的务实的开源活动,今年释放的三个挑战项目都实现了不错的开源导师传帮带效果:
- Greptime & 开源之夏完美收官
- 邹伟:从 0 到 1 迈出开源世界第一步
- 实现 Truncate Table 功能
- 实现滑动采样窗口函数的语法及计算
- 实现对 Duration 和 Interval 数据类型的支持
第二个是 GreptimeDB 的 good-first-time issue 流转速度极快,大部分容易上手的工作往往在一周甚至两三天内就会有人认领,并且完成的情况也还不错。实际认领实现过程中,只要你能够主动更新进展和提问,项目团队成员大多能及时回复。这个体验还是很难得的。
GreptimeDB 的未来发展期望
前面介绍 GreptimeDB 的时候,提到了开源、Rust、分布式、云原生、时序数据库等关键词。虽然这些 buzzword 确实也是 GreptimeDB 能力或特点的一部分,但是从注重实效的程序员(The Pragmatic Programmer)的角度来说,我们还可以做一个具体的展开。
即使当初市面上已经有“恒河沙数”的时序数据库存在,GreptimeDB 的创始团队还是发现了这些现存解决方案没能处理好的问题。对于时序数据当中重要的三个分类:指标(Metrics)、事件(Events)和日志(Logs),大多数时序数据库都只能最优化其中一到两种分类的存储和访问。
GreptimeDB 的创始团队认为,这三类数据可以共用同一套查询层和对象存储层能力,只需要针对各自的数据特性实现各自的存储引擎即可。其中大部分 DB 的架构和能力,例如数据分片、分布式路由,以及查询、索引和压缩等都可以共享。这样,GreptimeDB 最终能够成为同时提供所有时序数据最优化的存储和访问体验的单一系统。
开源应用监控项目 Apache SkyWalking 自研数据库 BanyanDB 也是基于相似的挑战和思考,不过它作为一个监控项目的子项目,更多是以相当特化的方式在实现。但是这反应了时序数据可以统一存储逐渐成为业内共识,所有的通用主流产品都将朝这个方向发展。
在仰望星辰大海的期许之外,GreptimeDB 也有脚踏实地的挑战。
例如,虽然我前面夸赞 GreptimeDB 的工程化水平不错,工程师做功能扩展和代码重构都能找到一个相对整洁的切面,但是软件工程是一个即使知道了原理和最佳实践,真正做出来还是有相当长的必要劳动时间的领域。在快速原型迭代的过程中,GreptimeDB 对内存和抽象的使用是相对奔放的。随着线上应用逐渐增多,GreptimeDB 团队也能收到用户上报的各种性能问题。这就要求重新关注到在快速开发过程里被刻意忽略的细节,精打细算关键路径上的内存使用,针对性能修改抽象以充分利用机器资源。这部分工作都是细致工作,讲究一个 benchmark 发现性能瓶颈并逐个优化。目前的 GreptimeDB 应该有相当多这样的优化机会。
例如,之所以过去时序数据库没能同时服务前面提到的三种不同数据,除了数据建模上的差异,更主要还是因为在数据量暴涨之后,特定数据类型的特定访问形式的读写性能会骤然降低。目前针对此类问题,业界提出了一系列索引方案进行改良。GreptimeDB 目前正在实现其中倒排索引的方案,也将探索结合倒排索引、基于 Cost 的查询优化器和 MPP 查询引擎的自适应方案。这些工作存在许多参与机会,目前 GreptimeDB 团队成员也有不少精力投入在此。
例如,系统层面数据一致性和性能之间的取舍依赖 WAL 模块的实现。目前,GreptimeDB 仅提供了本地的 RaftEngine 实现和 Kafka Remote 的实现,其中 Kafka Remote 的实现发布还不足三个月。这部分工作现在跟进来,参与到现有实现的完善和优化,以及可能的自研 WAL 设计实现过程当中,对任何数据系统开发者而言都将是一段宝贵的经历。
例如,GreptimeDB 在部署形式上支持云端同构部署,时序数据从设备端到云端都是同一套技术栈在处理。这时,如果 GreptimeDB 能够支持一些高级的分析能力,那么时序数据分析的成本将大大降低,体验也将进一步提高。目前,GreptimeDB 已经支持通过 SQL / PromQL / Python 脚本等形式执行分析,正在设计实现基于 Dataflow 技术的分析功能。分析的需求无穷无尽,这一部分对于熟悉数据分析的开发者来说,是一个很好的切入点。
核心数据库系统代码之外,GreptimeDB 还开源了完整的 Dashboard 方案和多语言客户端。再加上本身 GreptimeDB 就支持 SQL 和 PromQL 等业内通用接口,从 GreptimeDB 与生态集成的角度入手参与到 GreptimeDB 的发展,也是一条不错的道路。就在几天之前,我还看到有位同时使用 EMQX 和 GreptimeDB 的开发者向 GreptimeDB 的 Erlang 客户端提交补丁。
软件开发参与之外,Greptime 社群维护的两个重要渠道:GitHub Discussions 主题讨论平台与 Slack 即时通信工作空间都欢迎任何对 Greptime 开源和商业产品感兴趣的人加入。
GreptimeDB 的商业与可持续
我曾经表达过一个观点:商业化不是开源项目可持续的必要条件。因为许多开源软件是个人开发者兴趣所为,这些个人开发者可以有其他经济收入。即使不基于其创造的开源软件做商业变现,也不影响这些开源项目持续维护和发展。
不过,GreptimeDB 是 Greptime 公司研发的开源软件,而公司要想存续下去,就必须以某种形式取得盈利。Greptime 公司投入了不少资本和人力在 GreptimeDB 的研发上,那么 GreptimeDB 总要为 Greptime 的商业成功创造价值。
Greptime 公司目前有两条商业产品线:
- GreptimeCloud 提供了全托管的云上时序数据库服务,其内核是 GreptimeDB 系统。这个服务可以免费试用,其 Playground 和 Dashboard 做的技术品味都很好。
- GreptimeAI 是为 AI 应用提供可观测性的服务。不同于其他数据库在赶上 AI 浪潮时采用的 PoweredBy AI 增强自身产品的思路,GreptimeAI 是 For AI 增强 AI 产品的思路。其实本轮语言大模型带动的 AI 浪潮对 Database 服务本身的提升还十分有限,反而是这些 AI 应用自身产生的数据需要 Database 来存储和管理。
这两个产品的底层都是 GreptimeDB 的开源代码提供的核心能力,而云控制面、企业管理、安全集成等功能,则是商业代码实现的。
至于为什么要开源 GreptimeDB 数据库核心代码,而不是干脆全部都是私有的商业代码,前几天 Meta 的财报上介绍的 Llama 开源的理由帮我省去了很多口水:

应用在 GreptimeDB 的情况,在 Greptime 团队决心做这个产品的时候,先发的主流时序数据库已经取得极大的优势,且它们几乎全是开源的。这种情况下,就算 GreptimeDB 存在没有历史包袱的优势,直接朝着正确的方向飞奔,但是软件工程的固有复杂度和必要劳动时间并不能无限减少,所以开源是追赶现有主流产品和赢得用户信赖的必选项。
当然,开源软件允许任何用户免费使用,因此构建商业价值不能直接基于开源软件本身。关于 Greptime 如何设计开源模型,或许我会另写一篇文章做对比介绍。目前而言,其开源模型接近 Databricks 的策略。虽然 GreptimeDB 是从头开始写的,不像 Databricks 直接基于开源的 Apache Spark 构造解决方案,但是其核心功能实现重度复用了已有的开源软件:
- Apache Arrow DataFusion
- Apache OpenDAL
- TiKV RaftEngine
- Apache Kafka
- …
而且,Greptime 团队对于什么功能应该开源是谨慎的,而不是 by default 开源。只有存在这样一个踌躇推敲的过程,才有可能做商业可持续的战略开源。
DISCLAIMER
在社群参与过程中,我跟 GreptimeDB 的核心社群成员有深入的交流,并于近期加入了 Greptime 团队,因此我的观察和评价可能存在一定的主观误差。欢迎各位留言或私信交流意见。